从 Prompt 到工作流:用 LCEL 构建一个 AI 应用(上)
1. 为什么需要 LCEL:从单次问答到 AI 工作流
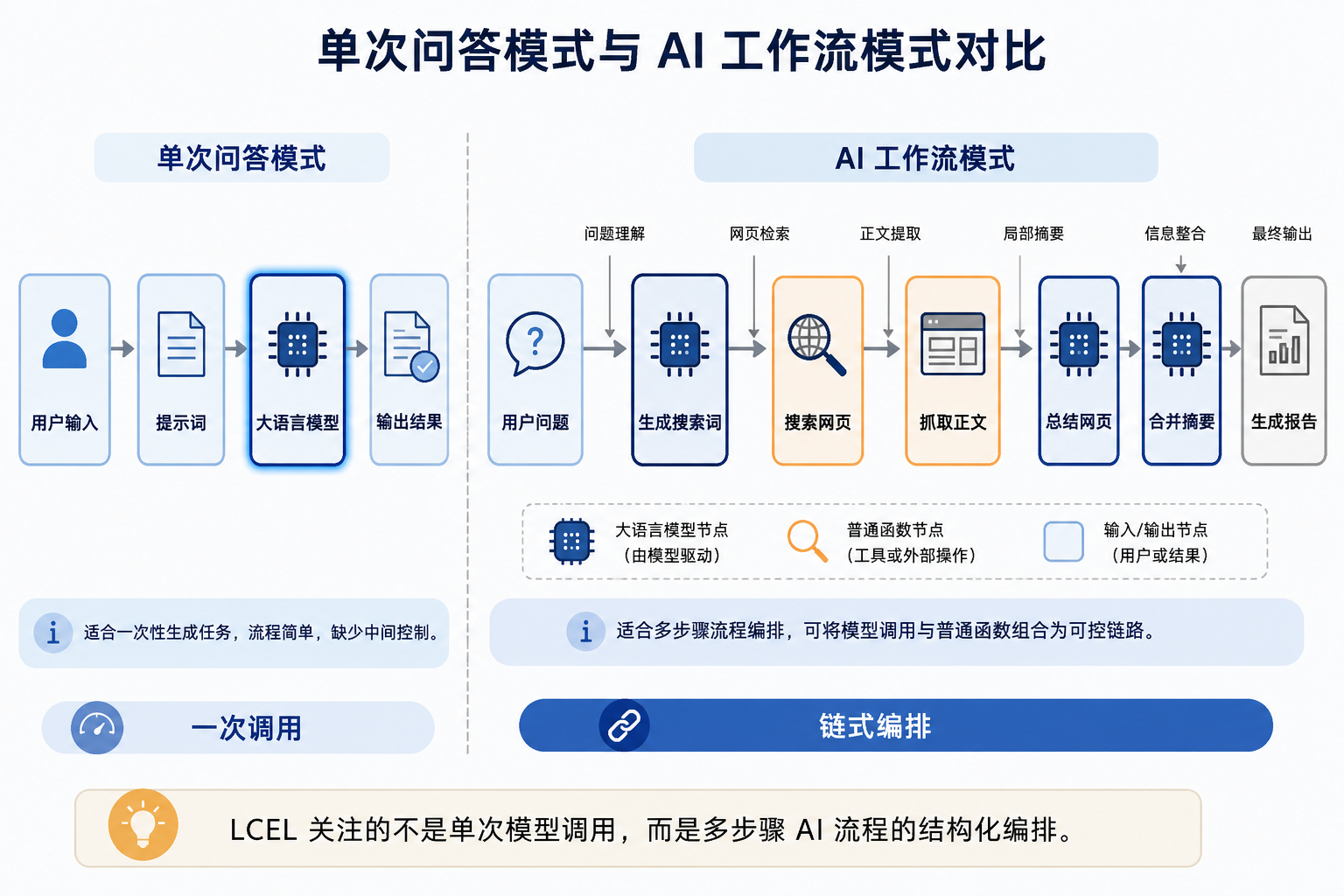
早期的LLM是一个简单的问答器,输入一个问题,拼接一段提示词,调用模型,然后返回结果。这种方式可以完成翻译、摘要、改写、问答等单步任务,但当从“回答一句话”变成“完成一个流程”时,单次调用就很难满足需求。
以“自动化网页研究总结”为例,目标不是简单回答一个问题,而是根据一个开放式问题,需要自动完成搜索、抓取、总结、整合和报告生成。比如输入:
1 | question = "杭州有哪些值得一去的地方?" |
这个问题表面上是问“杭州有哪些值得游览的景点和可以体验的地方?”,但要给出一份质量较高的研究报告,至少需要完成几类动作,比如说先理解问题所属领域,再生成多个搜索查询,然后获取搜索结果 URL,继续抓取网页正文,对每个网页进行摘要,最后把多个来源的信息合并成一个结构清晰的 Markdown 报告。
这类任务已经不再是单次模型调用,而是一个很典型的 AI 工作流。
1.1 单次问答的能力边界
单次问答的基本结构很简单,用户输入 → Prompt → LLM → 输出。
这种方式的优势是直接、轻量,适合处理输入明确、上下文较短、步骤单一的任务。例如,解释一个概念、改写一段文字、生成一段代码片段,都可以通过一次模型调用完成。
但网页研究总结案例是另一类问题。系统不能只依赖模型已有知识,因为网页内容可能变化,搜索结果也可能因时间、地区和来源不同而变化。更重要的是,用户期望得到的不是一段泛泛而谈的回答,而是基于多个网页来源整理出来的结构化内容。这意味着系统需要具备几个额外能力。
需要把宽泛问题拆解成多个可搜索的问题。例如,研究 杭州 时,直接搜索“杭州有哪些值得一去的地方”虽然可行,但结果往往会集中在热门景点榜单上,容易遗漏历史文化、自然景观、本地美食、交通路线和旅行建议等不同角度。更好的方式是让模型生成多个有针对性的搜索词,例如“杭州必去景点”“杭州历史文化景点”“杭州西湖游玩路线”“杭州本地美食推荐”“杭州两日游攻略”等。
需要接入外部工具。模型本身不会自动访问搜索引擎,也不会主动抓取网页内容。搜索网页、请求页面、解析 HTML、提取正文,这些都属于外部能力,需要由代码完成。
需要对多个中间结果进行处理和合并。一个搜索词可能返回多个 URL,多个搜索词又会产生更多网页。每个网页都需要单独抓取和总结,最后再把多个摘要合并成最终报告。
需要保留上下文和来源信息。网页摘要不能孤立存在。每条摘要最好附带来源 URL,并且在最终报告阶段保留与原始问题之间的关系。否则,系统很容易生成一篇看似完整但来源不清的内容。
因此,单次问答的“输入到输出”模式不足以满足这类任务。更合理的方式是把整个过程拆成多个清晰步骤,并让这些步骤按照稳定的数据流组合起来。
1.2 普通函数式写法的问题
一种直观做法是用普通 Python 函数串起整个流程:
1 | assistant = select_assistant(question) |
这种写法看起来清晰,也符合传统工程习惯。对于小脚本,它可用。但随着流程变复杂,也会有一些问题。
每一步的输入输出结构并不一致。角色选择链可能输出一个字典,搜索词生成链可能输出一个列表,网页搜索函数可能输出 URL 列表,网页总结链又需要同时接收网页正文、搜索词、URL 和原始问题。只要某一步字段命名不统一,后续流程就可能出错。
有些步骤需要调用模型,有些步骤只是普通函数。例如,生成搜索词和总结网页需要 LLM,而网页搜索和网页抓取主要依赖 Python 函数。如果全部写在一起,模型调用、数据转换、异常处理和业务逻辑会混在一起,代码很快变得难以维护。
批量处理和并行执行会变复杂。网页研究总结案例天然涉及多个搜索词、多个 URL、多个网页摘要。如果顺序执行,耗时会明显增加。假设生成 10 个搜索词,每个搜索词返回 10 个结果,系统就要处理 100 个网页。如果每个网页都串行抓取和总结,整体响应时间会非常长。
后续扩展成本较高。当系统需要加入流式输出、批处理、失败重试、日志追踪、异步执行或中间结果监控时,普通函数式写法需要手动补充大量控制逻辑。代码可以继续扩展,但结构会越来越重。
这并不是说普通函数不可用,而是说明,当 LLM 应用从“调用模型”升级为“编排流程”时,需要一种更适合表达工作流的数据组织方式。
1.3 LCEL 解决的核心问题
LCEL,全称是 LangChain Expression Language,可以理解为 LangChain 中用于编排 LLM 应用流程的一套表达方式。它的核心不是让代码看起来更简洁,而是让复杂流程中的 数据流、执行顺序和组件边界更加清晰。LCEL 最典型的写法是:
1 | chain = prompt | llm | parser |
这里的 | 表示前一个组件的输出,会自动作为后一个组件的输入。也就是说,提示词模板生成消息,消息传给模型,模型输出再交给解析器处理。整个过程可以被看作一条链。在简单场景下,这条链可能只有三段,Prompt → LLM → OutputParser
但在复杂场景下,链可以继续扩展,组合普通函数、模型调用、并行分支和批量处理。例如,网页研究总结可以拆成几条小链,角色选择链,搜索词生成链,URL 获取链,网页抓取与总结链,摘要合并链,报告生成链。
这些小链再组合成一条完整的研究报告生成链。这样做的好处是,每个步骤都有明确职责,每条链都可以单独测试,也可以整体组装。
LCEL 还提供了几个重要能力。
- RunnableLambda 可以把普通 Python 函数接入链中,用来做字段转换、数据清洗和结构重组。
- RunnableParallel 可以让同一份输入同时进入多个处理分支。例如,一边把网页正文交给模型总结,一边保留原始 URL 和用户问题。
- .map() 可以对列表中的每个元素执行同一条链,它非常适合处理多个搜索词、多个 URL 或多个网页片段。
这些能力恰好对应网页研究总结的核心需求:既要调用模型,又要调用外部函数;既要处理单个对象,又要批量处理列表;既要生成新内容,又要保留原始上下文。
1.4 LCEL 与其他流程编排框架
除了 LCEL,LLM 应用里还有一些类似的流程编排方式。它们解决的问题相近,但抽象层级不同。
如果流程是线性的,例如 Prompt → LLM → Parser → Function,LCEL 会比较自然。它的优势是轻量、直接,适合把多个组件串成一条数据流。
如果流程开始出现分支、循环、状态和条件跳转,就更适合使用 LangGraph。LangGraph 可以把应用建模成图,每个节点负责一个步骤,边表示执行流向。相比 LCEL,LangGraph 更适合多轮 Agent、人工审批、失败重试、状态保存等复杂场景。
如果需求是快速搭建问答、检索增强生成或数据查询应用,也可以使用 LlamaIndex Workflows。它更偏向数据和索引场景,适合围绕文档、知识库、检索器和查询流程构建应用。
还有一些更偏工程工作流的框架,例如 Haystack Pipeline、Semantic Kernel 和 Dify Workflow。它们同样可以把模型、工具、函数和外部服务组合起来,但侧重点不同。Haystack 更偏搜索和 RAG 管道,Semantic Kernel 更偏插件和企业应用集成,Dify 更偏可视化工作流和应用快速搭建。
因此,LCEL 不是唯一的编排方式。它更像是 LangChain 体系里最轻量的一层:适合表达清晰、边界明确的数据流。当流程变得越来越像一个有状态系统时,就应该考虑从 LCEL 过渡到 LangGraph;当重点是文档索引和检索时,可以考虑 LlamaIndex;当需要低代码界面和团队协作时,可以考虑 Dify 这类可视化工作流工具。
本文案例采用 LCEL,是因为网页研究总结流程虽然包含多个步骤,但整体仍然可以拆成一组清晰的数据流:生成搜索词、获取 URL、抓取网页、总结网页、合并摘要、生成报告。这个阶段使用 LCEL 足够直观,也方便读者理解 LangChain 中“组件如何连接”的核心思想。
1.5 从“模型调用”到“流程编排”
构建 LLM 应用时,一个常见误区是把重点全部放在模型本身,但在真实应用中,效果往往不只取决于模型能力,还取决于流程设计。网页研究总结案例就是一个很好的例子。模型负责理解问题、生成搜索词、总结网页和撰写报告,但系统真正的价值来自完整流程:
1 | 输入研究问题 |
其中每一步都不复杂,但组合在一起后,就从一个简单问答系统变成了一个自动化研究工具。LCEL 的作用,正是把这些步骤组织成可维护、可扩展、可并行执行的链式结构。
这也是从 Prompt 工程走向 AI 应用工程的关键,Prompt 只是单点能力,链式编排才是应用能力。
1.6 本文案例的目标
后续内容将围绕一个完整案例展开,使用 LCEL 构建一个自动化网页研究总结。系统接收一个研究问题,自动生成多个搜索查询,搜索相关网页,抓取网页内容,总结每个来源,并最终输出一篇 Markdown 格式的研究。这个案例的重点是为了说明 LCEL 如何组织 LLM 应用中的多个关键环节。具体来说,案例会覆盖以下能力:
- 使用 LCEL 串联 Prompt、模型和输出解析器,形成最基本的链式结构。
- 使用 RunnableLambda 处理链中的数据转换,解决不同步骤之间字段不一致的问题。
- 使用 RunnableParallel 同时执行多个分支,在总结网页的同时保留 URL 和原始问题。
- 使用 .map() 批量处理多个搜索结果,让多个网页可以进入同一条总结链。
- 将多个小链组合成完整工作流,最终生成结构化研究报告。
通过这个案例,可以看到 LCEL 为 LLM 应用提供一种更清晰的流程表达方式。普通函数仍然负责搜索、抓取和数据处理,LLM 负责理解、总结和生成,LCEL 则负责把这些能力连接起来。
小结
单次问答适合处理简单任务,但网页研究总结器需要完成一组连续动作,理解问题、拆解搜索、获取网页、抓取正文、总结内容、合并信息并生成报告。这个过程涉及模型调用、外部工具、数据转换、批量处理和结果整合,已经属于完整的 AI 工作流。
LCEL 的价值在于把这些步骤组织成清晰、可组合、可扩展的链式结构。它为复杂 LLM 应用提供稳定的数据流表达方式。后续章节将在这个基础上,逐步拆解 LCEL 的核心组件,并完成一个自动化网页研究总结案例。
2. 案例拆分:自动生成网页研究报告
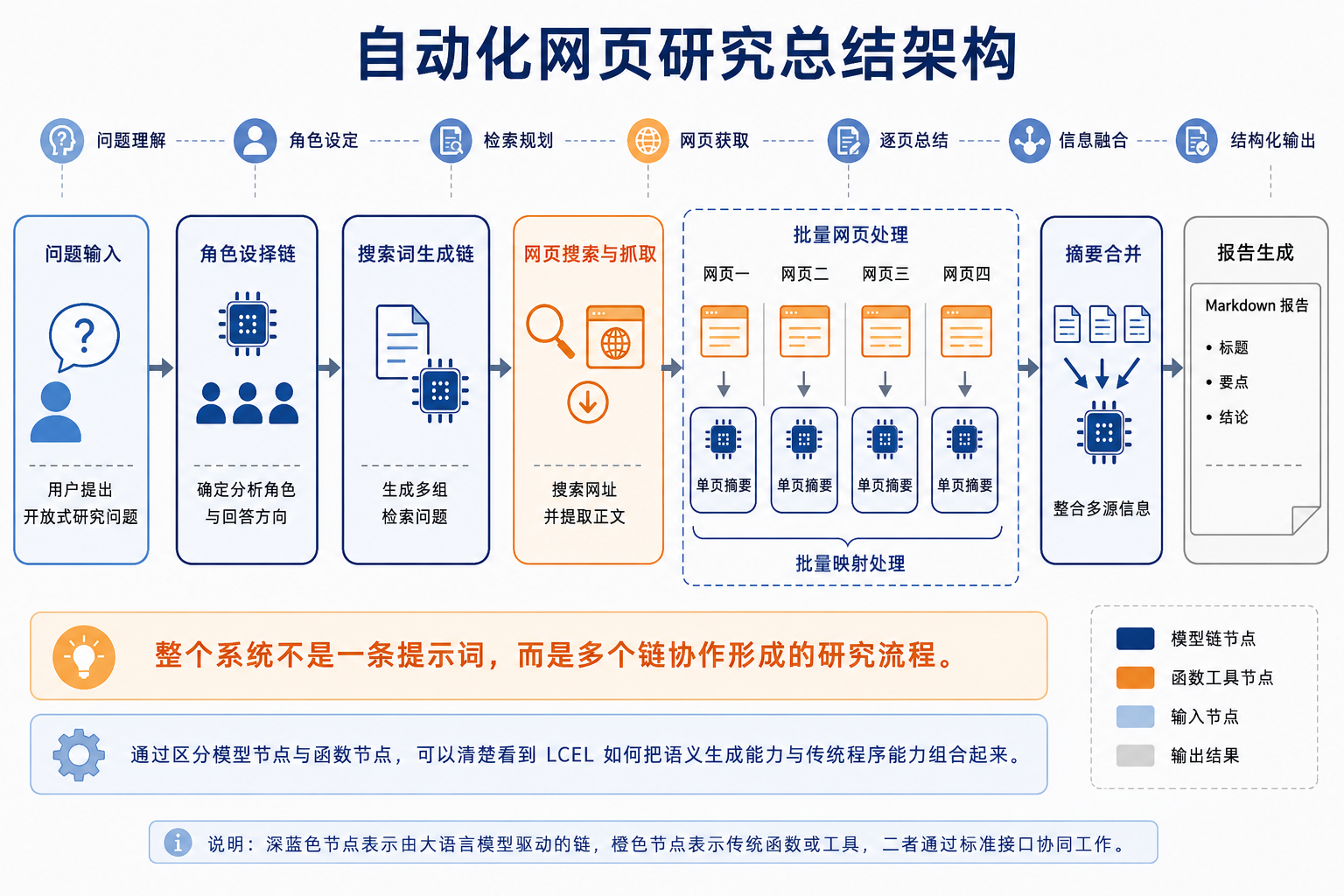
前文介绍了 LCEL 的核心组件与链式组合方式。本章开始构建一个 自动化网页研究总结器。它接收一个研究问题,自动生成搜索词、搜索网页、抓取内容、总结信息,并最终输出一篇结构化的 Markdown 报告。
这个案例通过一个完整流程说明:LCEL 如何把模型能力、普通函数和数据转换组合成可维护的 AI 应用。
2.1 任务目标与输出形式
输入的问题还是:
1 | question = "杭州有哪些值得一去的地方?" |
这个问题看似简单,但如果要生成一份有参考价值的研究报告,系统不能只让模型直接回答。更合理的做法是围绕这个问题主动收集网页信息,再基于多个来源进行整理。最终输出可以是一篇 Markdown 报告。从工程角度看,这个系统的输入和输出很明确:
| 项目 | 内容 |
|---|---|
| 输入 | 一个研究问题 |
| 输出 | 一篇 Markdown 格式的研究报告 |
| 中间过程 | 搜索、抓取、摘要、合并、生成报告 |
这里的关键在于,最终报告不是一次模型调用直接生成,而是由多个中间步骤逐步构建出来。在这个流程中,模型负责语义理解和文本生成,普通函数负责搜索、抓取和数据处理,LCEL 则负责把这些步骤连接起来。
2.2 系统链路设计
为了让流程清晰可维护,可以将自动化网页研究总结器拆成几条相对独立的链。每条链只负责一个明确任务,最后再组合成完整工作流。
2.2.1 角色选择链
它根据用户问题判断当前任务更适合哪类助手。例如,旅行类问题可以选择“旅行研究助手”,技术类问题可以选择“技术分析助手”。在本案例中,角色选择链可以输出类似结果:
1 | { |
这一步的作用不是形式化地添加角色,而是为后续搜索词生成和报告写作提供更明确的方向。
2.2.2 搜索词生成链
它把原始问题拆解为多个适合搜索引擎使用的查询。例如:
1 | [ |
这样做的好处是覆盖面更完整。一个宽泛问题被拆成多个角度后,搜索结果更可能包含景点、历史、文化、体验和实用信息。
2.2.3 网页搜索与抓取链
它根据搜索词获取网页 URL,再抓取网页正文。这一阶段主要由普通 Python 函数完成,不需要模型参与。模型不擅长直接访问网页,搜索和抓取应该交给工具完成。
2.2.4 网页摘要链
它针对每个网页生成摘要,并保留来源 URL。摘要结果可以整理为:
1 | { |
保留来源 URL 很重要。它可以让后续报告有信息来源,也便于排查某条内容来自哪个网页。
2.2.5 报告生成链
它把多个网页摘要合并起来,生成一篇结构化报告。此时模型输入的不再是杂乱网页正文,而是经过整理的摘要集合,因此最终输出更容易保持清晰。
整体链路可以表示为:
1 | question |
这个结构体现了 LCEL 的设计方式:先把复杂任务拆成小链,再把小链组合成完整应用。
2.3 数据结构与项目组织
链式应用最容易出错的地方,通常不是模型调用,而是字段衔接。上一条链输出什么,下一条链需要什么,必须提前设计清楚,本案例中会反复使用几个核心字段。
| 字段 | 含义 |
|---|---|
user_question |
原始中文问题 |
assistant_role |
助手角色 |
assistant_instructions |
助手执行说明 |
search_query |
中文搜索词 |
result_url |
搜索结果 URL |
search_result_text |
抓取到的网页正文 |
summary |
网页摘要 |
research_summary |
多个摘要合并后的研究材料 |
为了让代码结构与流程结构一致,可以采用如下项目目录:
1 | web-research-lcel/ |
最终调用时,主程序可以保持简洁:
1 | from chains.research_chain import web_research_chain |
这段代码只暴露了最终链,复杂逻辑被封装在不同模块中。外部看起来像调用一个普通函数,内部实际上完成了搜索、抓取、摘要和报告生成。
小结
系统输入一个研究问题,经过搜索词生成、网页搜索、正文抓取、网页摘要和报告整合,最终输出一篇 Markdown 格式的研究报告。
本案例的核心并不是让模型直接“凭空写报告”,而是把研究过程拆成多个清晰步骤。模型负责理解、生成和总结,普通函数负责搜索、抓取和数据处理,LCEL 负责把这些能力连接成稳定的数据流。
从下一章开始,将进入基础能力准备阶段:统一初始化 LLM,封装网页搜索函数,封装网页抓取函数,并为后续链式组合打好工程基础。
3. 基础能力:LLM 初始化、网页搜索与网页抓取
接下来需要准备三个基础能力:模型调用、网页搜索、网页抓取。这三部分并不直接构成完整应用,但它们是后续 LCEL 链能够运行的底层支撑。
自动化网页研究总结器的核心流程可以理解为,模型负责理解和生成,工具负责获取外部信息,LCEL 负责把二者连接起来。因此,在真正编写角色选择链、搜索词生成链和网页总结链之前,需要先把模型、搜索函数和抓取函数封装好。
本章重点不是追求复杂封装,而是建立一个清晰、稳定、可复用的基础层。
3.1 初始化 LLM
在 LCEL 链中,模型会被多次调用,例如生成搜索词、总结网页内容、生成最终报告。如果每条链都单独写一遍模型配置,代码会变得重复,也不利于后续替换模型。
更好的做法是把模型初始化封装到一个独立函数中,例如放在 llm_models.py 文件里:
1 | import os |
这段代码有几个关键点,首先,API Key 从环境变量中读取:
1 | CHAT_COMPLETIONS_API_KEY = os.getenv("CHAT_COMPLETIONS_API_KEY") |
然后在程序启动时加载环境变量。这样做更安全,也方便在不同运行环境中切换配置。其次,base_url 指向兼容 OpenAI 接口的模型服务:
1 | DASHSCOPE_BASE_URL = "https://dashscope.aliyuncs.com/compatible-mode/v1" |
虽然这里使用的是 ChatOpenAI 类,但并不意味着只能调用 OpenAI 官方模型。只要模型服务兼容 OpenAI Chat Completions 接口,就可以通过 base_url 接入。最后,temperature 设置为 0,研究总结类任务更重视稳定性与一致性。搜索词生成、网页摘要和最终报告都应该尽量减少随机发挥,因此低温度更合适。
封装完成后,后续链中只需要调用:
1 | from llm_models import get_llm |
或者直接写入 LCEL 链:
1 | chain = prompt | get_llm() | parser |
这样,模型配置被集中管理,链的主体结构也更干净。
3.2 封装网页搜索函数
网页研究总结器不能只依赖模型已有知识,它需要从外部网页中获取信息。搜索函数的职责是,根据搜索词返回一组网页 URL。可以使用 DuckDuckGo 搜索包装器实现一个简单版本,例如web_searching.py
1 | from typing import List |
这个函数接收两个参数:
| 参数 | 含义 |
|---|---|
web_query |
搜索词 |
num_results |
返回结果数量 |
输出是 URL 列表:
1 | [ |
需要注意,搜索函数只负责获取 URL,不负责理解网页内容,也不负责判断结果是否足够可靠。它在系统中的位置很明确,搜索词 → 搜索函数 → URL 列表。例如,输入搜索词:
1 | urls = web_search( |
可能得到多个相关网页链接。后续网页抓取函数会根据这些链接获取正文,再交给模型总结。
这里有一个容易忽略点,搜索函数最好保持简单,不要在里面混入摘要逻辑。搜索、抓取、总结是三个不同职责。如果全部写进一个函数,后续很难单独替换搜索工具,也很难定位失败原因。
3.3 封装网页抓取函数
搜索函数返回 URL 后,系统还需要访问网页并提取正文。这个过程由网页抓取函数完成。
可以使用 requests 获取网页 HTML,再用 BeautifulSoup 提取文本,例如web_scraping.py
1 | import requests |
这段代码做了几件事。
- 设置请求头:
1 | headers = { |
很多网站会根据请求头判断访问来源。如果不设置 User-Agent,请求可能被拒绝。Accept-Language 则表示优先接受中文内容,其次接受英文内容。
- 设置超时时间:
1 | timeout=15 |
网页请求不能无限等待。如果某个网站响应缓慢,系统应及时返回错误信息,避免整个链路卡住。
- 提取网页文本:
1 | soup = BeautifulSoup(response.text, "html.parser") |
这一步会把 HTML 中的文本提取出来,并用空格分隔不同文本片段。
不过,这种方式只是基础抓取。网页正文中可能仍然包含导航栏、页脚、广告、版权说明等噪声。因此,后续摘要 Prompt 需要明确要求模型围绕用户问题提取有效信息,而不是机械总结整页文本。
还需要考虑上下文长度问题。网页正文可能非常长,直接传给模型可能超过上下文限制。因此,在进入摘要链之前,需要对正文进行截断:
1 | RESULT_TEXT_MAX_CHARACTERS = 20000 |
这是一种简单但实用的处理方式。它不能保证保留网页中所有重要内容,但可以避免输入过长导致模型调用失败。后续如果需要更高质量,可以改成分块摘要或正文提取算法。
3.4 准备工具函数与配置项
除了模型、搜索和抓取,还需要准备少量工具函数和常量配置。
搜索词生成链通常会要求模型输出 JSON 字符串,后续程序需要把它转换成 Python 对象。可以在 utilities.py 中放置一个简单函数:
1 | import json |
后续可以直接接入 LCEL 链:
1 | chain = prompt | get_llm() | StrOutputParser() | to_obj |
同时,可以集中定义一些常量:
1 | NUM_SEARCH_QUERIES = 3 |
这些参数分别表示:
| 配置项 | 含义 |
|---|---|
NUM_SEARCH_QUERIES |
生成多少个搜索词 |
NUM_SEARCH_RESULTS |
每个搜索词返回多少个网页 |
RESULT_TEXT_MAX_CHARACTERS |
每个网页最多传入多少字符 |
例如,当 NUM_SEARCH_QUERIES = 3 且 NUM_SEARCH_RESULTS = 3 时,系统最多会处理 9 个网页。这个规模适合作为案例演示,既能体现多来源研究,又不会让执行时间过长。
这里有个注意点,搜索词数量和搜索结果数量相乘后,会直接影响模型调用次数。如果每个网页都需要一次摘要调用,那么网页数量越多,整体耗时和成本都会上升。因此,这些配置不应随意调大。
3.5 基础模块之间的关系
准备好基础能力后,系统的底层模块关系可以概括为:
llm_models.py,提供 get_llm()web_searching.py,提供 web_search()web_scraping.py,提供 web_scrape()utilities.py,提供 to_obj()
它们不会单独完成最终任务,但会被后续各条链调用。例如,搜索词生成链会用到:
1 | get_llm() |
URL 搜索链会用到:
1 | web_search() |
网页总结链会用到:
1 | web_scrape() |
最终报告链会用到:
1 | get_llm() |
这种模块划分能够保持职责清晰。模型初始化、搜索、抓取、解析分别独立,后续如果某一部分需要替换,不会影响整个项目。
例如,搜索工具从 DuckDuckGo 换成 Tavily 或 SerpAPI,只需要改 web_searching.py;网页抓取从 requests + BeautifulSoup 换成更专业的正文提取工具,只需要改 web_scraping.py;模型从 deepseek-v4-pro 换成其他兼容接口模型,只需要改 llm_models.py。
基础能力封装的目标不是复杂,而是稳定、清晰、可替换。
小结
本章完成了自动化网页研究总结器的基础能力准备。get_llm() 负责统一初始化模型,web_search() 负责根据中文搜索词获取网页 URL,web_scrape() 负责抓取网页正文,to_obj() 负责将模型输出的 JSON 字符串转换为 Python 对象。
这些基础函数本身并不复杂,但它们决定了后续链路是否清晰可维护。模型、搜索、抓取和解析被拆成独立模块后,LCEL 链可以专注于流程编排,而不是把所有细节堆在一起。
从下一章开始,将基于这些基础能力构建第一条实际链路:角色选择链,让系统先根据中文问题判断任务类型,并生成适合后续研究流程的助手设定。
4. 角色选择链:让系统先理解任务类型
基础能力准备完成后,可以开始构建第一条 LCEL 链:角色选择链。
在自动化网页研究总结器中,角色选择链位于整个流程的起点。它接收用户问题,判断当前任务更适合哪种研究助手,并生成一段用于后续流程的助手说明。这个步骤不会直接搜索网页,也不会生成最终报告,但它会影响后续搜索词生成、网页摘要和报告写作的方向。
例如,当前问题是:
1 | question = "杭州有哪些值得一去的地方?" |
系统应识别出这是一个旅行研究问题,而不是技术分析、商业调研或体育评论。对应的助手设定应该偏向旅行规划、景点介绍、文化背景、本地体验和实用建议。
4.1 为什么需要角色选择链
如果直接把用户问题交给搜索词生成链,系统也可以生成一些搜索词。但这样做会缺少任务视角。同样是“杭州有哪些值得一去的地方?”,不同研究目标会导致完全不同的搜索方向。
如果目标是旅行研究,搜索词应关注:
1 | 杭州 必去景点 |
如果目标是历史文化研究,搜索词可能更偏向:
1 | 杭州 南宋历史文化 |
如果目标是城市体验研究,搜索词又会偏向:
1 | 杭州 城市漫步 路线 |
因此,角色选择链的价值在于:先判断问题的研究视角,再让后续链围绕这个视角展开。
这一步并不是为了让系统显得更“智能”,而是为了减少后续搜索和摘要的发散。对于开放式问题,研究视角越明确,搜索词越容易聚焦,最终报告也越容易形成清晰结构。
4.2 设计角色选择提示词
角色选择提示词的目标,是让模型根据用户问题输出一个结构化结果。这个结果至少包含三类信息:
1 | assistant_role |
其中,assistant_role 表示当前任务适合哪类研究助手;assistant_instructions 表示后续搜索、摘要和报告生成时应该重点关注什么;user_question 用来保留原始问题,方便后续链继续使用。
可以在 prompts.py 中定义如下提示词:
1 | from langchain_core.prompts import ChatPromptTemplate |
这里有几个设计细节。
提示词要求模型只输出 JSON,这是为了方便后续解析。如果模型在 JSON 前后添加说明文字,
json.loads()可能会解析失败。提示词中明确给出了可选助手类型。这样做可以减少模型自由发挥,避免一会儿输出“旅行助手”,一会儿输出“旅游规划专家”,一会儿又输出“城市探索助手”。字段越稳定,后续链越容易处理。
输出中保留了
user_question。这是因为整个系统后面还需要继续使用原始问题。如果角色选择链只输出角色和指令,后续搜索词生成链就可能失去最初的任务目标。
4.3 用 LCEL 实现角色选择链
有了提示词后,可以先定义一条 角色选择子链:
1 | import json |
这条子链的结构是:
1 | Prompt → LLM → 字符串解析 → JSON 转 Python 对象 |
执行后,它会得到一个 Python 字典,例如:
1 | { |
不过,在完整流程里,我们通常不会只调用这个子链。为了让后续链拿到统一格式的数据,可以在utilities.py中定义一条 角色指令链:
1 | # 角色指令链,输入 user_question,先调用角色选择子链,再把结果整理成后续链需要的字段。 |
这段代码分成两步。
第一步,输入是:
1 | { |
第一个 RunnableLambda 会保留原始问题,并调用 assistant_selection_chain:
1 | RunnableLambda(lambda x: { |
执行后,中间结果大致是:
1 | { |
第二步,展开 assistant_result:
1 | RunnableLambda(lambda x: { |
最终输出会变成一个扁平结构:
1 | { |
这样后续链就可以直接读取:
1 | x["user_question"] |
而不需要写成:
1 | x["assistant_result"]["assistant_instructions"] |
调用方式如下:
1 | result = assistant_instructions_chain.invoke({ |
可能输出:
1 | { |
4.4 角色选择链的输出检查
角色选择链虽然简单,但它是后续流程的入口,因此需要关注输出稳定性。理想输出应满足几个条件。
第一,必须是合法 JSON。否则后续 to_obj() 会解析失败。
第二,必须包含固定字段:
1 | assistant_role |
第三,assistant_role 最好来自提示词中定义好的候选类型,而不是模型临时编造的角色名称。否则后续如果要根据角色做条件分支,会比较麻烦。
第四,assistant_instructions 要对后续任务有实际帮助。例如下面这种输出价值较低:
1 | { |
它过于泛化,无法指导搜索词生成。更合适的输出是:
1 | { |
这样的说明会直接影响下一步搜索词。因此,角色选择链虽然位于流程开头,却会影响整个研究方向。
不过也要注意,角色选择链不是越复杂越好。如果系统只处理单一类型任务,比如只做旅行攻略,那么角色选择链可以省略,直接把系统固定为“旅行研究助手”。只有当系统需要支持多类问题时,角色选择链才有明显价值。
前面的杭州案例会被分配给旅行研究助手。但角色选择链的意义并不只体现在旅行问题上。当前提示词中还配置了多种助手类型,例如 财经研究助手、体育研究助手、技术研究助手 和 通用研究助手等。当用户问题发生变化时,模型会根据任务类型选择不同角色。
例如,当问题变成投资分析:
1 | result = assistant_instructions_chain.invoke({ |
可能输出:
1 | { |
可以看到,同一条角色选择链并没有绑定在“旅行”这一类任务上。它会先判断问题属于哪种研究场景,再把后续流程引导到对应的信息关注重点上。对于投资问题,后续搜索词生成就不应该围绕景点、美食或路线,而应该围绕公司财报、估值、业务增长、行业竞争和风险因素展开。
这也说明了角色选择链的核心价值:它不是为了给回答套一个角色名称,而是为了提前确定后续搜索和总结的研究视角。
小结
本章构建了自动化网页研究总结器的第一条链:角色选择链。它接收问题,判断任务类型,并生成适合后续搜索和报告写作的助手设定。这条链的结构是用户问题 → 角色选择 Prompt → LLM → JSON 解析 → 助手设定。
在实际代码中,为了保留原始问题并给后续链提供统一字段,本章采用了两层结构:
- assistant_selection_chain:负责调用模型,生成角色选择结果。
- assistant_instructions_chain:负责保留 user_question,并整理输出字段。
角色选择链的关键不是输出一个好看的角色名称,而是为后续搜索词生成和报告整合提供明确方向。 当研究视角被提前确定,后续链路就能围绕同一目标展开,避免搜索和摘要过度发散。
下一章将继续构建搜索词生成链,把原始问题和助手设定转换成多个可用于网页搜索的查询。
5. 搜索词生成链:把用户问题拆成多个搜索查询
角色选择链解决了“系统应该从什么角度理解任务”的问题,但它还没有真正开始获取外部信息。要让网页研究总结器进入资料收集阶段,下一步需要把用户问题转换成多个适合搜索引擎使用的查询词。
这一章构建 搜索词生成链。它接收用户问题和助手设定,输出一组搜索查询。后续 URL 搜索链会根据这些查询获取网页链接。
5.1 为什么要生成多个搜索词
开放式问题往往包含多个信息维度。以本案例问题为例:
1 | question = "杭州有哪些值得一去的地方?" |
如果只使用原始问题搜索,结果可能偏向综合旅游攻略,但未必覆盖所有重要角度。杭州这样的目的地,至少可以从以下几个方向检索:
| 方向 | 可能搜索词 |
|---|---|
| 景点概览 | 杭州 必去景点 |
| 自然风光 | 杭州 西湖 西溪湿地 自然景观 |
| 历史文化 | 杭州 灵隐寺 京杭大运河 南宋御街 历史文化 |
| 城市体验 | 杭州 城市漫步 湖滨 运河 夜游 |
| 美食茶文化 | 杭州 美食 龙井茶 河坊街 旅行攻略 |
这些查询并不是简单改写,而是把一个宽泛问题拆成多个搜索切面。这样可以减少信息遗漏,让后续摘要和报告更完整。角色选择链的输出也会参与搜索词生成。例如,上一章得到的助手说明可能是:
1 | { |
搜索词生成链就可以据此生成更贴近旅行研究目标的查询,而不是只围绕“杭州”这个地名做泛泛搜索。比如它会同时覆盖西湖、灵隐寺、西溪湿地、京杭大运河、龙井茶文化、城市漫步和美食体验等方向。这样后续抓取到的网页内容更容易形成结构化报告,而不是只得到一组重复度很高的景点榜单。
5.2 设计搜索词生成提示词
搜索词生成提示词需要完成两个目标:一是生成多个中文搜索查询,二是输出可被程序解析的结构化结果。可以在 prompts.py 中定义如下模板:
1 | WEB_SEARCH_PROMPT_TEMPLATE = ChatPromptTemplate.from_template( |
这个提示词的重点是让输出稳定。因为后续链需要直接读取 search_query 字段,所以输出必须是 JSON 数组。这里的字段设计延续了前面的数据结构:
1 | search_query:用于搜索引擎 |
保留 user_question 很关键。搜索词进入后续流程后,如果只剩下 search_query,网页摘要链就只能围绕搜索词总结,而无法明确最终要回答的问题。通过保留原始问题,后续模型在摘要网页时仍然知道任务目标。
5.3 用 LCEL 实现搜索词生成链
搜索词生成链的输入来自角色选择链的三个字段:
1 | user_question |
其中 num_search_queries 是配置项,不一定来自上面条链。因此,需要使用 RunnableLambda 补充字段,再进入 Prompt。
1 | NUM_SEARCH_QUERIES = 3 |
这条链可以分为四步,整理输入字段 -> 生成搜索词 Prompt -> 调用 LLM -> 解析 JSON 字符串。其中,RunnableLambda 的作用是明确输入结构:
1 | RunnableLambda(lambda x: { |
它把上一条链传来的数据整理成 Prompt 需要的格式。这里不直接把整个 x 传给 Prompt,是为了避免字段混乱,让链的输入规则更清晰。调用方式如下:
1 | input_data = { |
可能得到:
1 | [ |
此时输出的 Python 数组可以直接交给下一条 URL 搜索链处理。
5.4 输出质量与稳定性
搜索词生成链的质量会直接影响后续搜索结果。如果搜索词过宽,网页结果可能泛泛而谈;如果搜索词过窄,又可能遗漏重要信息。因此,这条链需要关注三个方面。
第一,搜索词要覆盖不同角度。对于杭州旅行类问题,至少应覆盖自然景观、历史文化、代表性景点、城市体验、美食茶文化和实用攻略。如果所有搜索词都只是“杭州旅游”或“杭州景点”,搜索结果会高度重复,后续报告也容易变成普通景点清单。
第二,搜索词要适合搜索引擎。搜索查询不应写成长句,也不应包含复杂解释。比如下面这种查询不太适合直接搜索:
1 | 请告诉我杭州有哪些值得一去的地方以及每个地方为什么值得去 |
更合适的是:
1 | 杭州 必去景点 西湖 灵隐寺 西溪湿地 |
或者:
1 | 杭州 历史文化 京杭大运河 南宋御街 博物馆 |
第三,输出必须可解析。搜索词生成链后面会接 to_obj(),如果模型输出不是合法 JSON,链会中断。为了提高稳定性,提示词中要明确要求“只输出 JSON 数组”。在更严格的工程实现中,还可以使用结构化输出解析器或加入异常重试机制。
这里也有个注意点,搜索词的语言会影响搜索结果覆盖面。对于杭州这类中文目的地,中文搜索词通常更容易找到本地攻略、景区信息、城市体验和中文旅行内容。但如果希望获得国际游客视角,也可以让模型同时生成英文搜索词,例如:
1 | [ |
不过本文案例保持中文主线,代码和问题均以中文为主。是否加入英文搜索词,可以作为后续优化方向。
小结
本章构建了搜索词生成链。它接收角色选择链输出的 user_question 和 assistant_instructions,补充搜索词数量配置,并通过模型生成多个中文搜索查询。
这条链的核心结构是,用户问题 + 助手说明 -> RunnableLambda 整理输入 -> 搜索词生成 Prompt -> LLM -> StrOutputParser -> JSON 转 Python 对象 -> 搜索查询列表。
搜索词生成链的关键价值,是把一个宽泛的问题拆成多个可检索的信息切面。 后续 URL 搜索链将基于这些查询获取网页来源,为网页抓取和摘要生成提供资料入口。
6. 总结:从 Prompt 到可组合链路
上篇完成的是整个 LCEL 应用的前半段:先说明为什么单次 Prompt 调用无法支撑复杂任务,再把自动化网页研究总结器拆成一组职责清晰的小链。到这里,系统已经具备了三个关键能力:理解用户问题所属的任务类型,生成适合该任务的助手说明,并把宽泛问题拆成多个可搜索的查询。
这几章的重点不是追求链式语法本身,而是建立一种工程化思路:先拆任务,再定义每一步输入输出,最后用 LCEL 把 Prompt、模型、解析器和普通函数连接起来。角色选择链让后续生成有明确方向,搜索词生成链则把用户问题转换成可以进入外部世界的信息入口。
但到上篇结束时,系统还没有真正拿到网页资料。搜索词只是研究计划,不能直接生成可靠报告。下篇会继续完成后半段链路:把搜索词转换成 URL,抓取网页正文,总结每个来源,批量处理多个网页,并最终把所有中间结果组装成一篇 Markdown 研究报告。也就是说,上篇解决“如何规划研究”,下篇解决“如何获取资料并生成结果”。
7.备注
完整代码:https://github.com/keychankc/AI_agent_code/tree/main/web-research-lcel