RAG 入门:从零实现检索增强生成
1. 大模型的知识边界与问答局限
很多 AI 应用在面对简单问题时往往表现不错。通过 Prompt 输入问题,大模型能够生成流畅且看似合理的回答,看起来已经具备知识助手的能力了。但如果进入真实业务场景后,这种能力边界就会逐渐显现。例如询问昨天刚更新的公司制度,或者追问内部文档中的具体细节,模型依然可能给出完整且自然的回答,但其中的信息并不一定准确。
原因是模型会说,不代表模型真的知道。 很多人第一次使用大模型时会产生一种错觉。模型回答流畅、表达自然、知识丰富,于是容易认为模型像数据库一样存储了大量事实,并且能够随时准确调用。
事实并非如此。大模型擅长的是基于当前输入生成最可能的下一段文本,不是实时查数据库,也不会自动验证资料。当问题依赖具体文件、内部数据或数据在最近更新时,只靠模型参数就不够了。
本文要解决的是这样一个问题,如何让模型不只是生成答案,而是先找到资料,再基于资料回答。
1.1 大模型并不真正拥有实时知识
大模型知道的东西,主要来自训练阶段。训练时,它读过大量文本,把语言模式和事实关联压缩进参数里。训练结束后,这些参数不会因为外部世界变化而自动更新。这会带来两个直接问题。
知识天然存在时间边界
模型完成训练之后,参数通常不会实时更新。因此训练之后发生的新事件、最新版本信息或企业内部变化,并不会自动进入模型能力范围。例如询问,某个产品昨天发布了什么功能?如果训练数据里没有相关内容,模型无法直接获取。模型无法主动访问外部系统
企业中的真实知识往往分散在多个地方:内部 Wiki、PDF 文档、知识库、制度文件、项目文档、数据库、历史记录
这些内容默认并不存在于模型参数里。即使允许上传文档,也只能解决一次性的上下文问题,不适合作为长期知识库。更现实的是,上下文窗口再大也不是无限的。假设有个几百页的项目文档,每次提问都把全文塞进 Prompt,可能就会出现几个问题:
- Token 成本迅速增长
- 响应时间明显变慢
- 模型容易受到无关内容干扰
- 上下文长度终究存在上限
所以,问题不只是“模型够不够强”,而是资料应该怎样加载到模型中。
1.2 从一个简单问答例子开始
为了说明问题,可以先看一个最简单的场景。假设存在一段关于古城遗址的介绍文本:
1 | 良渚古城遗址拥有三重城址结构,外围水利系统由良渚先民修建。... |
直接把问题和文本一起发送给模型:
1 | 阅读以下内容并回答: |
模型通常能够回答:
1 | 有三重城址结构;外围水利系统由良渚先民修建。 |
这个过程看起来像搜索,实际上并不是。模型真正做的是:
1 | 读取上下文 → 理解问题 → 组织语言 → 输出答案 |
上下文(Context) 不是知识库,而是模型当前一次推理过程中能够看到的信息。只要问题答案存在于上下文里,模型通常能够完成提取和组织,这也是很多聊天机器人的工作方式。
把信息塞给模型,让模型回答,这种方式在小规模场景非常有效。但如果继续追问:
1 | 这些城墙一共有多长? |
如果原文没有写,模型可能依然给出一个看起来合理的数字,甚至会解释原因。但这些内容并不存在于资料里。为什么会这样。
1.3 幻觉是生成机制的结果
这种现象通常被称为幻觉(Hallucination)。 幻觉是生成机制的自然结果。模型的默认目标不是判断资料够不够,而是在当前上下文下继续生成合理文本。于是当上下文不足时,它往往不会停下来,而是继续补全。例如:
1 | 问题: |
上下文没有答案,模型内部可能发生:
1 | 古城 → 考古知识 → 估算城墙长度 → 生成回答 |
结果就是语言合理,事实却可能是错的。模型越强大,这种错误反而越难发现,因为它看起来很像真的。因此评价一个知识问答系统,不能只看它能不能回答,还要看它在资料不足时会不会停下来。
为了降低幻觉,最直接的方法不是更换模型,而是约束信息来源,例如在 Prompt 中明确说明:
1 | 仅允许依据提供内容回答。若上下文没有答案,请明确说明无法确定。 |
这样模型会更倾向输出:
1 | 当前资料未提供相关信息。 |
虽然没有答案,但至少没有编。接下来要做的就是把这件事系统化:先找到资料,再让模型基于资料回答。这就是 RAG 要解决的问题。
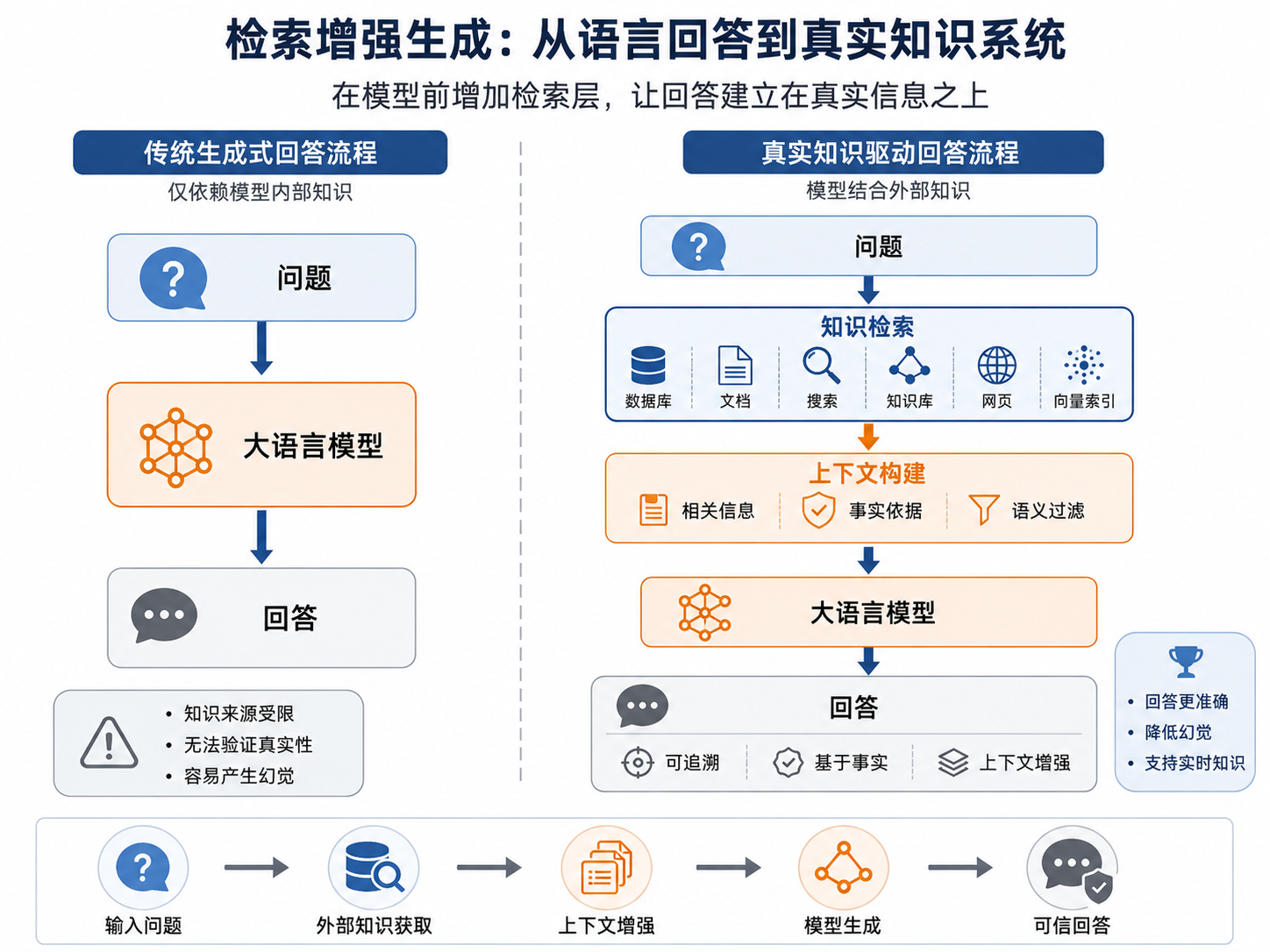
2. RAG 到底解决了什么问题
前面说了一件事,资料少的时候,把内容直接塞进 Prompt 就够了。但资料一多,或者答案依赖外部文件,只靠模型自己回答就会不稳定。
这里要拆开的是两个分工职责。模型负责理解和表达,知识库负责保存资料,检索系统负责把相关资料找出来。也就是先找资料,再生成答案。
2.1 什么是检索增强生成(RAG)
RAG,全称 Retrieval-Augmented Generation,通常翻译为检索增强生成,名字本身已经说了整个过程。
- Retrieval 表示检索。
- Augmented 表示增强。
- Generation 表示生成。
把三个阶段连起来,就是先找到相关资料,再把资料作为上下文交给模型,最后由模型生成回答。整体过程如下:
1 | Question → Retrieve → Context → LLM → Answer |
这看起来只是多了一步搜索,但数据流已经变了。相比传统问答方式,知识完全来自模型训练,而 RAG 的流程变成:
1 | 用户问题 → 知识检索 → 上下文增强 → 模型生成 |
知识开始来自外部系统,模型不再承担“记住一切”的任务。它更像人在工作时查资料,先翻到相关页,再组织答案。
2.2 从全文输入到按需检索
理解 RAG 最直观的方法,就是对比两种知识输入方式。
先看传统方案,假设存在一份两百页的企业制度文档,为了回答问题,把全部内容直接交给模型:
1 | Question + Whole Document → LLM |
上下文窗口有限,长文档会占满输入;成本也会变高,因为每次提问都要重复发送整份文档。更严重的是信息噪声,模型看到太多无关内容后,回答质量反而下降。例如问题:
1 | 报销金额超过多少需要审批? |
相关内容可能只有几十行,模型却要读完整份文档。更合理的做法是先把相关片段找出来,只把这些片段交给模型,流程变成:
1 | Question → Search → Relevant Context → LLM |
这就是按需检索。模型不用每次从头读完整份资料,只处理当前问题需要的部分。
2.3 从模型知识到外部知识
第一次接触 RAG 时,很容易误以为它是一种新的模型能力。其实 RAG 没有改变模型本身,改变的是模型拿到信息的方式。
可以把传统模型理解成闭卷考试。训练结束后,参数固定,回答完全依赖记忆。而 RAG 更像开卷考试,允许在回答前先查资料,模型依然负责理解和表达。但知识来源发生变化,整个系统:
| 组件 | 职责 |
|---|---|
| 知识源 | 存储真实数据 |
| 检索系统 | 找到相关内容 |
| 上下文构造 | 组织输入 |
| LLM | 理解并生成 |
这种分工带来了几个关键变化。
- 知识更新不再依赖重新训练,新增一份文档,更新知识库即可。
- 知识边界开始突破模型参数。内部资料、业务系统、实时数据都能接入。
- 回答过程变得可解释。可以知道模型参考了哪些内容。
所以,后面调 RAG 效果时,重点不会只是换模型,还要看资料怎么存、怎么搜、怎么放回 Prompt。接下来的问题是,既然知识不放在模型里,那这些知识应该放在哪里?系统又如何找到相关内容?这就需要向量数据库了。
3. 向量数据库为什么成为 RAG 的基础设施
现在知识不再放进模型参数里,而是放在外部系统里。那用户问一句话时,系统怎么从一堆资料里找到相关内容?最直接的想法通常是搜索。
1 | 问题: |
去文档里搜索:
1 | 报销、审批、金额 |
看起来合理,但实际效果往往并不好。因为现实里的知识并不会永远按照提问方式出现。问题和答案之间,经常存在表达差异。
这时,单纯关键词搜索就不够用了。需要解决的是,如何让机器找相近含义,而不是只找相同单词。
3.1 为什么关键词搜索不够
传统搜索建立在匹配机制上,输入什么词,搜索什么词。例如存在这样一段文本:
1 | 良渚古城外围水利系统由良渚先民修建。 |
现在提出问题:
1 | 谁修建了这些水坝? |
如果搜索系统只做关键词匹配,可能出现:
1 | 水坝 ≠ 水利系统 |
最终无法命中,因为文本里没有出现完全相同的词语。这种问题在真实场景中更明显。例如,
1 | 文档写: |
人能够理解这些表达对应同一个意思,关键词搜索通常做不到。因此问题需要从找相同文字,变成找相同含义。这就是语义搜索。它不关心是否出现同样单词,而关注表达的内容是否相近。 为了做到这一点,就需要先解决另一个问题,机器如何计算语义。
3.2 Embedding:把语义变成数字
机器无法直接理解文字,它只能计算数字。因此语义搜索第一步,是把文本转换成数字表示。这个过程叫:Embedding(向量化表示)。 过程如下:
1 | 文本 → Embedding → 向量 |
例如一句简单文本:
1 | 猫 |
经过 Embedding 后:
1 | [0.17,-0.63,0.81,...] |
这里得到的并不是编码结果,而是语义空间中的坐标。单个数字没有什么可解释的意义,重要的是整组数字所在的位置。例如猫、狮子、老虎,这些词虽然完全不同,但可能聚集在相近区域。而与汽车、数据库、咖啡的距离则明显更远。
于是有了一种新的搜索方式,不再搜索单词,而是比较位置,整体逻辑变成:
1 | 问题 → Embedding → 向量 → 计算距离 → 返回最近内容 |
距离越近,说明语义越接近。这也是向量搜索成立的基础。
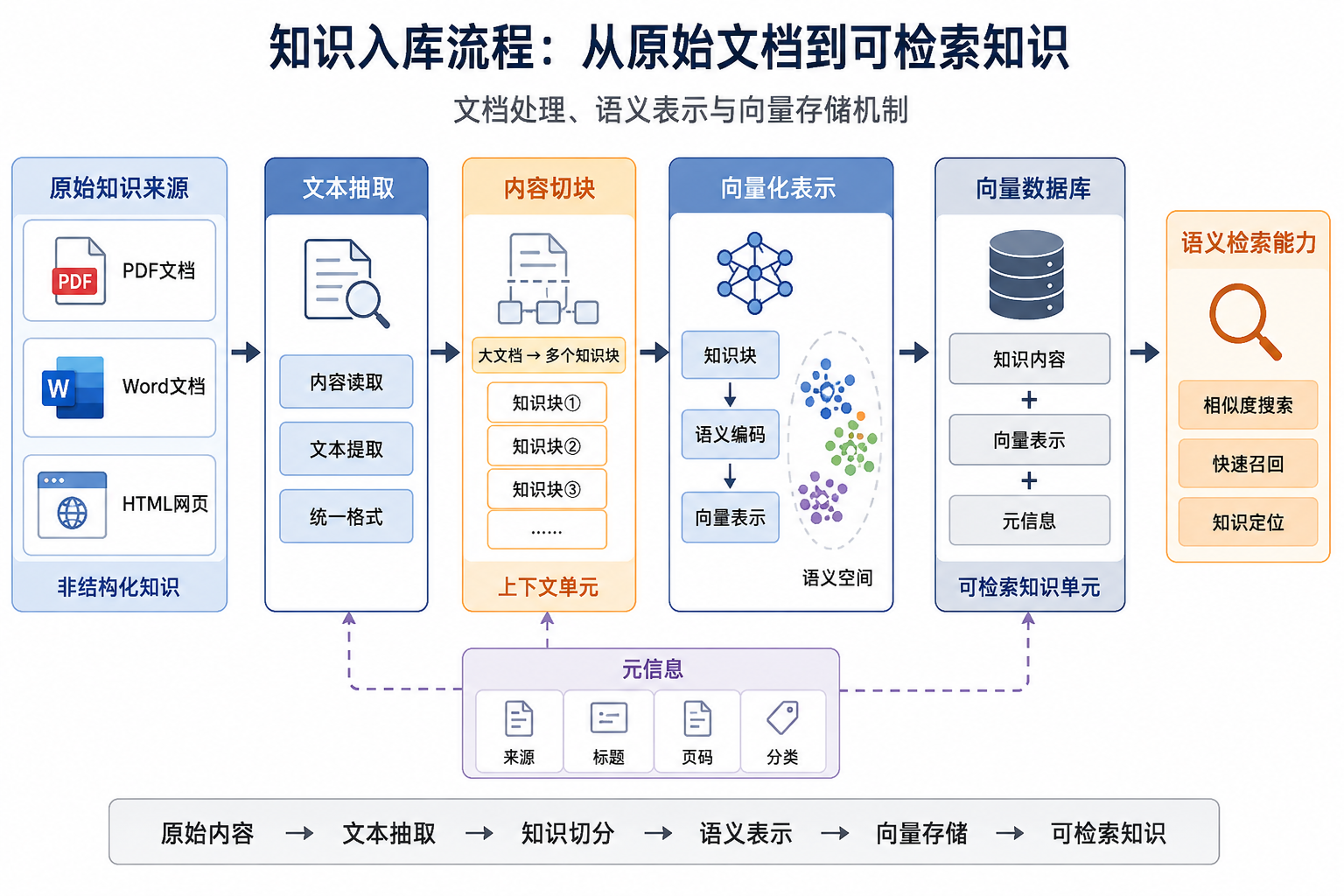
3.3 Indexing:知识如何转化为可检索数据
有了向量之后,还不能直接开搜。现实里的知识通常不是一句话,而是一份份文档。可能包含:
1 |
|
这些内容无法直接拿去搜索,需要先完成知识加工。这个过程通常称为Indexing(索引构建) 或者Content Ingestion(内容摄取)。整个过程通常如下:
1 | Document → Chunk → Embedding → Vector Store |
这四步就是把原始资料变成可检索数据的过程。我们先看第一步。
3.3.1 文档切块(Chunk)
长文本通常不会整体进入向量库。Embedding 模型存在输入长度限制,整篇检索精度太低。例如一份制度文件有100页,不会直接得到一个向量,而会拆成:
1 | Chunk1 |
每一段单独生成向量。以后搜索时,只返回和问题接近的片段。切块策略会直接影响检索效果,如果切得太长,相关内容容易被噪声覆盖;切得太短,上下文容易丢失。因此 Chunk 大小通常是 RAG 系统的重要调优参数。
3.3.2 元数据(Metadata)
除了正文,通常还会保存额外信息,例如:
1 | source |
这些信息不参与语义计算,但方便后续过滤和追踪。例如,只搜索:
1 | 技术文档 |
元数据开始承担结构化检索能力。
3.3.3 向量生成(Embedding)
切块完成后,每个 Chunk 被转换成向量,形成:
1 | Chunk + Embedding + Metadata |
最后写入向量数据库。这里要注意一点:数据库里通常不会只保存向量,还会保留原始文本。因为检索命中之后,最终要交给模型的仍然是内容本身。
现在资料已经变成了向量。下一步就是把这些向量存起来,并支持按语义距离搜索。
4. 用 Chroma 构建向量知识库
前面大致讲了下流程,现在开始代码。目标是把几段文本存进向量数据库,再用一句问题把相关文本搜出来。
这一部分使用 Chroma。它足够轻量,不需要先搭一套复杂服务,很适合用来理解一段文本是怎么被写入、向量化、再被检索出来的。
4.1 初始化 Chroma
开始之前,需要先准备 Python 环境。下面的命令可以直接在终端执行:
1 | pip install chromadb openai langchain-openai notebook |
这篇文章里会用到两类模型:
- Embedding 模型:负责把文本转成向量。
- Chat 模型:负责基于检索结果生成回答。
不要把密钥直接写进代码里,可以加到环境变量中
1 | export CHAT_COMPLETIONS_API_KEY="API Key" |
这里不再单独准备 OpenAI 的 Key。Embedding 和 Chat 都走 OpenAI 兼容接口,只是使用的模型不同。
随后创建 Chroma client、embedding function 和 LLM。这里的重点是,Chroma 负责存储和检索,embedding 模型负责把文本变成向量,Chat 模型负责最后生成答案。
1 | import os |
这里的 text-embedding-v4 是文本向量模型。它的作用不是生成回答,而是把文本转换成一组向量数字。后面 Chroma 做相似度搜索时,比较的就是这些向量之间的距离。也就是说:
1 | 原始文本 → text-embedding-v4 → 向量 → Chroma 保存和检索 |
这段代码会创建一个本地 Chroma 实例,当前是内存模式(In-memory)。 程序结束后数据会消失,实际项目通常会使用持久化存储。接着创建一个 Collection,并把 embedding function 绑定进去:
1 | tourism_collection = chroma_client.create_collection( |
Collection 可以理解成:
1 | Database |
就像关系型数据库的对应关系
1 | MySQL → Database → Table |
Collection 本质上就是一组向量数据的逻辑集合,例如tourism_collection、employee_rules、project_notes、support_faq。不同知识域通常对应不同 Collection。容器准备好后,就可以开始写入知识了。
4.2 导入文档并自动生成向量
假设已经准备好几段文本。每一段文本就是一个最小知识片段,也就是前文提到的 Chunk:
1 | documents = [ |
再准备每个 Chunk 的来源信息。metadatas 不参与向量相似度计算,但后面可以用来告诉用户答案来自哪里:
1 | metadatas = [ |
开始写入数据库:
1 | tourism_collection.add( |
这里会看到三个字段:
documents表示原始文本。metadatas表示来源、页码、标题等附加信息。ids表示唯一标识。
代码跑起来后,Chroma 内部发生的是:
1 | 文本 → Embedding → 向量 → 保存 |
最终进入数据库的数据包含 Document、Embedding、Metadata、ID。也就是说,数据库既保存原始内容,也保存语义表示。文本现在已经可以被语义搜索命中。
4. 开始语义搜索
知识写入完成,开始进行第一次检索:
1 | results = tourism_collection.query( |
这几行代码背后做了三件事:把问题转成向量,和库里的文本向量比较距离,返回最近的文本。结果可能类似:
1 | { |
注意,数据库并不是在搜索三重 这个词。它比较的是问题向量和文档向量之间的距离。因此如果这样问:
1 | 良渚古城有几层结构? |
也可能得到同样结果,因为表达方式不同,语义仍然接近。
4.4 相似度搜索的工作原理
为了更清楚理解过程,可以返回多个结果,代码如下:
1 | results = tourism_collection.query( |
返回结果可能类似:
1 | 文本: 遗址中的水坝至今保存较好 |
这里的距离代表语义相似度。 距离越小,说明越相关。整体过程如下:
1 | Question → Embedding → Vector → Distance → Ranking → Top K |
这就是向量数据库和传统关键词检索的差别。关键词检索更像是在问“有没有这个词”,向量检索更像是在问“意思像不像”。不过现在它还只是把资料找出来,并不会回答问题。
下一步,还要把检索结果交给模型,让模型基于资料组织答案。
5. 将检索结果引入大模型生成
现在系统已经能搜到相关内容,但返回的仍然只是 Chunk。这些只是原始文本。还需要把它们交给大模型,让模型读完资料后组织成自然语言答案。
5.1 封装检索函数
前面的查询代码能够返回结果,但仍然比较底层。为了方便后续调用,先把检索逻辑抽象成函数。示例代码如下:
1 | def query_vector_database(question, n_results=1): |
整个函数负责输入问题,返回最相关内容,例如:
1 | context = query_vector_database( |
得到:
1 | ["良渚古城遗址拥有三重城址结构"] |
这里的职责需要做一下拆分,之前是:
1 | Question → LLM |
现在:
1 | Question → Retriever → Context |
模型不再凭空回答,而是先消费检索器给它的上下文。
5.2 构造 Prompt,让模型基于资料回答
检索结果已经拿到,下一步是把结果塞进 Prompt。最简单的方法是字符串拼接:
1 | def build_prompt(question, context): |
这段 Prompt 里最关键的是这一句:
1 | 只根据提供的上下文回答 |
这句话用来限制模型,只能依据资料回答,不要自行补全。随后调用模型:
1 | question = "良渚古城有几重城址结构?" |
这样,检索和生成就接上了。
1 | Question → Retrieve → Context → Prompt → LLM |
此时模型回答问题时,已经开始依赖外部资料。
5.3 简单但完整 RAG 工作流
把前面的片段合在一起,就是下面这份完整可运行的版本:
1 | import os |
这份代码的完整执行过程如下。
- 用户提出问题,
良渚古城有几重结构? - 问题进入检索层,
Question → Embedding → Similarity Search - 返回相关文本,
良渚古城遗址拥有三重城址结构 - 构造 Prompt,
Question + Retrieved Context - 模型生成最终答案
链路可以写成:
1 | User Question → Embedding → Vector Search → Top K Context → Prompt → LLM → Answer |
这就是最小版 RAG:先搜,再答。
5.4 困难问题的验证
为了验证系统是否真的依赖知识,而不是继续猜答案,可以重新使用前面的例子。提问:
1 | 这些城墙一共有多长? |
注意,知识库里并没有记录城墙总长度。系统执行:
1 | Question → Retrieve → Context → Generate |
最终得到:
1 | 无法根据提供资料确定。 |
这个结果因为模型没有编,它选择停下来。这里最核心的点是输入方式变了。以前模型只看到问题,现在模型看到:
1 | Question + Evidence |
生成范围被资料限制住了。
**5.5 当前实现的 RAG **
回头看知识流是:
1 | Document → Chunk → Embedding → Vector Store → Retrieve → Context → Prompt → LLM → Answer |
每一层负责一件事。
| 组件 | 职责 |
|---|---|
| Embedding | 理解语义 |
| Vector DB | 搜索资料 |
| Retriever | 召回内容 |
| Prompt | 组织上下文 |
| LLM | 生成答案 |
这样后面继续优化时,就不只是改 Prompt 了,还要改切块、检索、上下文组织和模型回答策略。
6. 重新理解 RAG 的价值
前面已经跑通了第一版 RAG,文本先进入向量库,问题再去检索,最后由模型基于检索结果回答,最后再回顾一下。
6.1 检索与生成彻底解耦
在传统大模型应用里,知识和能力高度耦合。训练结束之后:
1 | 模型 = 知识 + 能力 |
想获得新知识,通常意味着重新训练、继续微调、重新部署。但业务资料更新得太快,不可能每改一份制度就动一次模型,很多东西会变,项目文档会变,产品信息会变,但模型参数不会自动变化。RAG 的做法是把知识从模型里拿出来,形成新的结构:
1 | 知识 → 检索层 → 模型 |
各个分工职责也更清楚。
| 组件 | 职责 |
|---|---|
| 知识库 | 保存真实信息 |
| 向量数据库 | 完成召回 |
| Retriever | 组织检索 |
| Prompt | 构造上下文 |
| LLM | 理解与生成 |
这样一来,模型不再承担存储职责,主要负责理解和表达。应用要维护的重点,也从“让模型记住什么”变成了“资料怎么更新、怎么检索、怎么放进上下文”。
6.2 为什么 RAG 能降低幻觉
幻觉的一个来源是,模型在证据不足时仍然会继续生成。传统模式下,回答可能语言自然,但事实错误。RAG 在模型前面加了一层检索,让模型先拿到证据,再组织答案,回答范围就会被收窄。
以前模型只看到问题。现在模型看到的是问题加上下文。如果上下文里没有答案,它更容易输出“无法确定”,而不是继续推测,这里有一个容易忽略的变化:过去我们容易期待系统永远有答案;做知识问答时,更应该关注答案有没有证据。
所以,RAG 里的一个基本原则是:没有证据,不输出结论。
6.3 第一版 RAG 的局限
虽然第一版系统已经能跑,但它还只是Minimal RAG。 真正做项目时,还会遇到很多细节问题,比如说,
- 知识切块大小如何确定。
- 返回几个结果最合适。
- 如何避免上下文重复。
- 如何提升召回准确率。
- 如何处理长文档。
- 如何支持实时更新。
这些问题都会影响回答质量。
例如同一个问题,切块过大,相关内容可能被无关文字淹没;切块过小,上下文又容易断;返回太多,模型容易偏离重点;返回太少,信息不够。因此实际工程中,RAG 往往会继续扩展:
1 | Hybrid Search: 同时用关键词搜索 + 向量搜索,既能搜语义,也能搜精确词。 |
这些不是这篇要展开的内容。先知道一件事就够了,RAG 能跑起来只是第一步,后面还需要在检索质量和上下文质量上继续调整。
6.4 从 Prompt Engineering 到系统工程
很多 AI 应用一开始都在调 Prompt。知识规模变大之后,只调 Prompt 就不够了,系统里会多出几层东西:
1 | Data |
模型只是其中一环。很多工作会发生在模型之外。例如:
- 知识管理。
- 检索优化。
- 上下文管理。
- 工作流编排。
所以,RAG 的重点不是把 Prompt 写得更长,而是把资料处理好,数据如何进入系统、知识如何被召回,以及上下文如何被组织。
7. 总结:让模型从“会说”走向“会查”
回到最开始的问题,普通 AI 聊天为什么不够用?因为模型擅长生成,却不适合保存和获取业务资料。RAG 做的事,就是让模型先查资料,再回答。整个过程中有几次关键转换。
- 文本被切块。
- 内容被向量化。
- 知识进入向量数据库。
- 问题触发检索。
- 模型基于上下文回答。
链路可以写成:
1 | Data → Chunk → Embedding → Vector DB → Retrieve → Prompt → LLM → Answer |
这就是第一版 RAG 的完整链路。后面无论做知识助手、企业问答,还是更复杂的 Agent 系统,基本都绕不开这条线。
8.备注
完整代码:https://github.com/keychankc/AI_agent_code/tree/main/lang-chain-rag